Google Search Gets Smarter With Knowledge Graph

Share
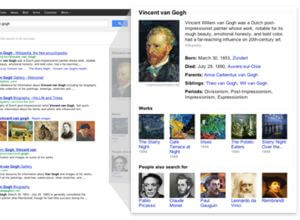
This week Google is rolling out a new search tool: the Knowledge Graph. Breaking with the old strategy of keywords and webpages, Knowledge Graph makes use of the vast amounts of online data to give you persons, places, and things that are related to what you're looking for. This new search philosophy of "Things Not Strings" ceases to treat your query as a random string of characters, and treats them as real world ideas instead. And it's only the beginning of the move away from having to wade through website after website to find what you're looking for.
Without Knowledge Graph, Google search results are keyword-based and direct us to websites that contain our keyword or related keywords. But as we know words are often ambiguous. For example, if you type in “mercury” you could be interested in the elemental liquid, the planet, or the fleet-of-foot messenger of the Roman gods. By being connected to a network of relevant material, results become more narrow, getting us to our relevant “mercury” more quickly. They’re richer too, allowing us easy access to information about the first planet from the sun.
Now, instead of Googling to get to the Wikipedia page, much of the information you’re looking for will already be displayed in the results – a Googlepedia. Sort of.
When searching for a book, dog breed, or planet, an information panel will appear in that empty white space to the right of the results list. The section will contain a brief description, a collection of facts, the highest-ranking related images, related searches, and other related information such as a map, an upcoming concert for a band, or recently Google+ posts from people in your circles.
The information display won’t be nearly as complete as a Wikipedia page, and not all topics get an information display. Easily packaged subjects like specific sports teams, movies, locations, and famous people get a display. Cars, video games, and companies do not.
Of course, your facts are only as good as your sources. The Knowledge Graph draws from multiple online data sources including Wikipedia, the CIA World Factbook, and Freebase, an open database generated by Metaweb, which Google acquired in 2010. Wikipedia has nearly four million articles, and Freebase has data on over 24 million people, places, and things. Subject-specific information is gathered from sites like Weather Underground for weather and the World Bank for global economics. As before, data from Google searches are used to make educated guesses of what people are searching for and what webpages they want to see. They’ve only just started building it up, but already the Knowledge Graph includes 500 million people, places, and things with connections to 3.5 billion attributes. And the bewildering network of connections will be honed by people using it with a feature that allows users to point out incorrect or irrelevant information.
Like the real world and information about it, the Knowledge Graph is a work in progress. Here’s a short video that describes how Google is reshaping itself from an “information engine to a knowledge engine.”
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

What will Google look like after the Knowledge Graph has had 5 or 10 years to gobble up databases? If it’s true that Google was already making us dumber, get ready to donate a few more IQ points for the sake of convenience.
For many searches we probably won’t notice the “extra knowledge” in the results (incidentally, the Graph has yet to grace the Google page on my laptop), but already we can see where all of this is going. Along with Google, tools like WolframAlpha and Siri, have conditioned people to expect more out their software – they want useful information and they want it quick and easy. Google Chrome's text to speech function makes that happen, and so do Google Glasses. It doesn't get any easier than looking at things and talking to yourself. The Knowledge Graph adds to these as part of Google's effort to both shape the direction that people interact with technology, and to stay relevant and competitive in this increasingly AI-driven world.
[image credits: Google via YouTube]
[video credits: Google via YouTube]
images: Google
video: Google via YouTube
Peter Murray was born in Boston in 1973. He earned a PhD in neuroscience at the University of Maryland, Baltimore studying gene expression in the neocortex. Following his dissertation work he spent three years as a post-doctoral fellow at the same university studying brain mechanisms of pain and motor control. He completed a collection of short stories in 2010 and has been writing for Singularity Hub since March 2011.
Related Articles

The First AI‑Designed Vaccine Has Been Tested in People. Here’s What Happened.

Forget Code: AI Is Learning to Hack Society

AI Collapses on a Classic Psychology Test. What It Reveals Could Stall Human-Level AI.
The First AI‑Designed Vaccine Has Been Tested in People. Here’s What Happened.
Forget Code: AI Is Learning to Hack Society
AI Collapses on a Classic Psychology Test. What It Reveals Could Stall Human-Level AI.
What we’re reading