New Spiking Neuromorphic Chip Could Usher in an Era of Highly Efficient AI
Share
When it comes to brain computing, timing is everything. It’s how neurons wire up into circuits. It’s how these circuits process highly complex data, leading to actions that can mean life or death. It’s how our brains can make split-second decisions, even when faced with entirely new circumstances. And we do so without frying the brain from extensive energy consumption.
To rephrase, the brain makes an excellent example of an extremely powerful computer to mimic—and computer scientists and engineers have taken the first steps towards doing so. The field of neuromorphic computing looks to recreate the brain’s architecture and data processing abilities with novel hardware chips and software algorithms. It may be a pathway towards true artificial intelligence.
But one crucial element is lacking. Most algorithms that power neuromorphic chips only care about the contribution of each artificial neuron—that is, how strongly they connect to one another, dubbed “synaptic weight.” What’s missing—yet tantamount to our brain’s inner working—is timing.
This month, a team affiliated with the Human Brain Project, the European Union’s flagship big data neuroscience endeavor, added the element of time to a neuromorphic algorithm. The results were then implemented on physical hardware—the BrainScaleS-2 neuromorphic platform—and pitted against state-of-the-art GPUs and conventional neuromorphic solutions.
“Compared to the abstract neural networks used in deep learning, the more biological archetypes…still lag behind in terms of performance and scalability” due to their inherent complexity, the authors said.
In several tests, the algorithm compared “favorably, in terms of accuracy, latency, and energy efficiency” on a standard benchmark test, said Dr. Charlotte Frenkel at the University of Zurich and ETH Zurich in Switzerland, who was not involved in the study. By adding a temporal component into neuromorphic computing, we could usher in a new era of highly efficient AI that moves from static data tasks—say, image recognition—to one that better encapsulates time. Think videos, biosignals, or brain-to-computer speech.
To lead author Dr. Mihai Petrovici, the potential goes both ways. “Our work is not only interesting for neuromorphic computing and biologically inspired hardware. It also acknowledges the demand … to transfer so-called deep learning approaches to neuroscience and thereby further unveil the secrets of the human brain,” he said.
Let’s Talk Spikes
At the root of the new algorithm is a fundamental principle in brain computing: spikes.
Let’s take a look at a highly abstracted neuron. It’s like a tootsie roll, with a bulbous middle section flanked by two outward-reaching wrappers. One side is the input—an intricate tree that receives signals from a previous neuron. The other is the output, blasting signals to other neurons using bubble-like ships filled with chemicals, which in turn triggers an electrical response on the receiving end.
Here’s the crux: for this entire sequence to occur, the neuron has to “spike.” If, and only if, the neuron receives a high enough level of input—a nicely built-in noise reduction mechanism—the bulbous part will generate a spike that travels down the output channels to alert the next neuron.
But neurons don’t just use one spike to convey information. Rather, they spike in a time sequence. Think of it like Morse Code: the timing of when an electrical burst occurs carries a wealth of data. It’s the basis for neurons wiring up into circuits and hierarchies, allowing highly energy-efficient processing.
So why not adopt the same strategy for neuromorphic computers?
A Spartan Brain-Like Chip
Instead of mapping out a single artificial neuron’s spikes—a Herculean task—the team honed in on a single metric: how long it takes for a neuron to fire.
The idea behind “time-to-first-spike” code is simple: the longer it takes a neuron to spike, the lower its activity levels. Compared to counting spikes, it’s an extremely sparse way to encode a neuron’s activity, but comes with perks. Because only the latency to the first time a neuron perks up is used to encode activation, it captures the neuron’s responsiveness without overwhelming a computer with too many data points. In other words, it’s fast, energy-efficient, and easy.
The team next encoded the algorithm onto a neuromorphic chip—the BrainScaleS-2, which roughly emulates simple “neurons” inside its structure, but runs over 1,000 times faster than our biological brains. The platform has over 500 physical artificial neurons, each capable of receiving 256 inputs through configurable synapses, where biological neurons swap, process, and store information.
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

The setup is a hybrid. “Learning” is achieved on a chip that implements the time-dependent algorithm. However, any updates to the neural circuit—that is, how strongly one neuron connects to another—is achieved through an external workstation, something dubbed “in-the-loop training.”
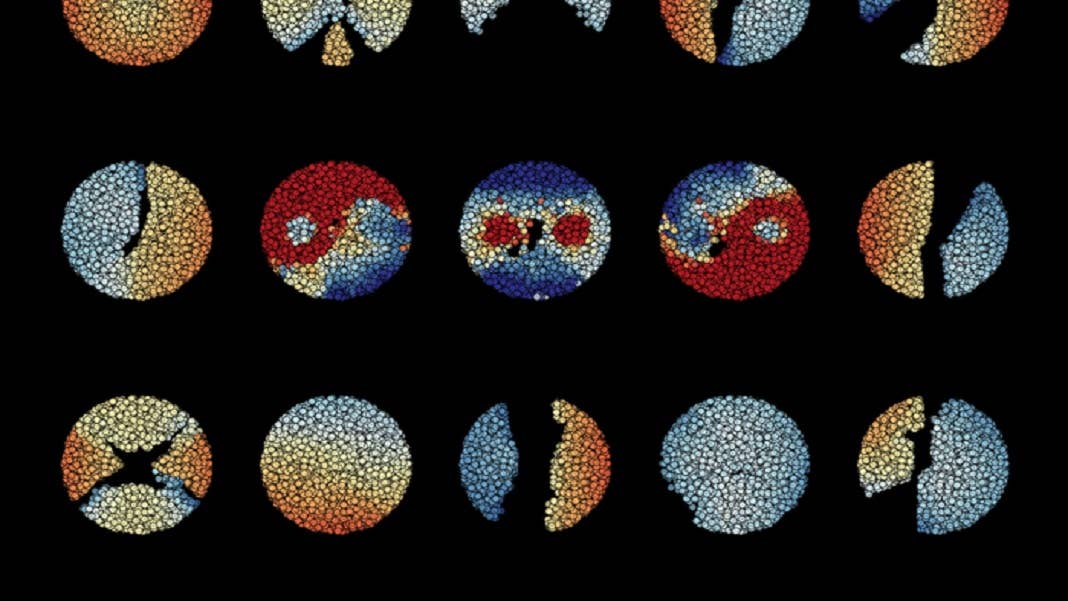
In a first test, the algorithm was challenged with the “Yin-Yang” task, which requires the algorithm to parse different areas in the traditional Eastern symbol. The algorithm excelled, with an average of 95 percent accuracy.
The team next challenged the setup with a classic deep learning task—MNIST, a dataset of handwritten numbers that revolutionized computer vision. The algorithm excelled again, with nearly 97 percent accuracy. Even more impressive, the BrainScaleS-2 system took less than one second to classify 10,000 test samples, with extremely low relative energy consumption.
Putting these results into context, the team next compared BrainScaleS-2’s performance—armed with the new algorithm—to commercial and other neuromorphic platforms. Take SpiNNaker, a massive, parallel distributed architecture that also mimics neural computing and spikes. The new algorithm was over 100 times faster at image recognition while consuming just a fraction of the power SpiNNaker consumes. Similar results were seen with True North, the harbinger IBM neuromorphic chip.
What Next?
The brain’s two most valuable computing features—energy efficiency and parallel processing—are now heavily inspiring the next generation of computer chips. The goal? Build machines that are as flexible and adaptive as our own brains while using just a fraction of the energy required for our current silicon-based chips.
Yet compared to deep learning, which relies on artificial neural networks, biologically-plausible ones have languished. Part of this, explained Frenkel, is the difficultly of “updating” these circuits through learning. However, with BrainScaleS-2 and a touch of timing data, it’s now possible.
At the same time, having an “external” arbitrator for updating synaptic connections gives the whole system some time to breathe. Neuromorphic hardware, similar to the messiness of our brain computation, is littered with mismatches and errors. With the chip and an external arbitrator, the whole system can learn to adapt to this variability, and eventually compensate for—or even exploit—its quirks for faster and more flexible learning.
For Frenkel, the algorithm’s power lies in its sparseness. The brain, she explained, is powered by sparse codes that “could explain the fast reaction times…such as for visual processing.” Rather than activating entire brain regions, only a few neural networks are needed—like whizzing down empty highways instead of getting stuck in rush hour traffic.
Despite its power, the algorithm still has hiccups. It struggles with interpreting static data, although it excels with time sequences—for example, speech or biosignals. But to Frenkel, it’s the start of a new framework: important information can be encoded with a flexible but simple metric, and generalized to enrich brain- and AI-based data processing with a fraction of the traditional energy costs.
“[It]…may be an important stepping-stone for spiking neuromorphic hardware to finally demonstrate a competitive advantage over conventional neural network approaches,” she said.
Image Credit: Classifying data points in the Yin-Yang dataset, by Göltz and Kriener et al. (Heidelberg / Bern)
Related Articles

Why Scientists Redesigned the Botox Enzyme With AI

OpenAI Agent Breaks Free and Hacks Hugging Face

Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?
Why Scientists Redesigned the Botox Enzyme With AI
OpenAI Agent Breaks Free and Hacks Hugging Face
Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?
What we’re reading