OpenAI Finds Machine Learning Efficiency Is Outpacing Moore’s Law

Share
Eight years ago a machine learning algorithm learned to identify a cat—and it stunned the world. A few years later AI could accurately translate languages and take down world champion Go players. Now, machine learning has begun to excel at complex multiplayer video games like Starcraft and Dota 2 and subtle games like poker. AI, it would appear, is improving fast.
But how fast is fast, and what’s driving the pace? While better computer chips are key, AI research organization OpenAI thinks we should measure the pace of improvement of the actual machine learning algorithms too.
In a blog post and paper—authored by OpenAI's Danny Hernandez and Tom Brown and published on the arXiv, an open repository for pre-print (or not-yet-peer-reviewed) studies—the researchers say they've begun tracking a new measure for machine learning efficiency (that is, doing more with less). Using this measure, they show AI has been getting more efficient at a wicked pace.
To quantify progress, the researchers chose a benchmark image recognition algorithm (AlexNet) from 2012 and tracked how much computing power newer algorithms took to match or exceed the benchmark. They found algorithmic efficiency doubled every 16 months, outpacing Moore's Law. Image recognition AI in 2019 needed 44 times less computing power to achieve AlexNet-like performance.
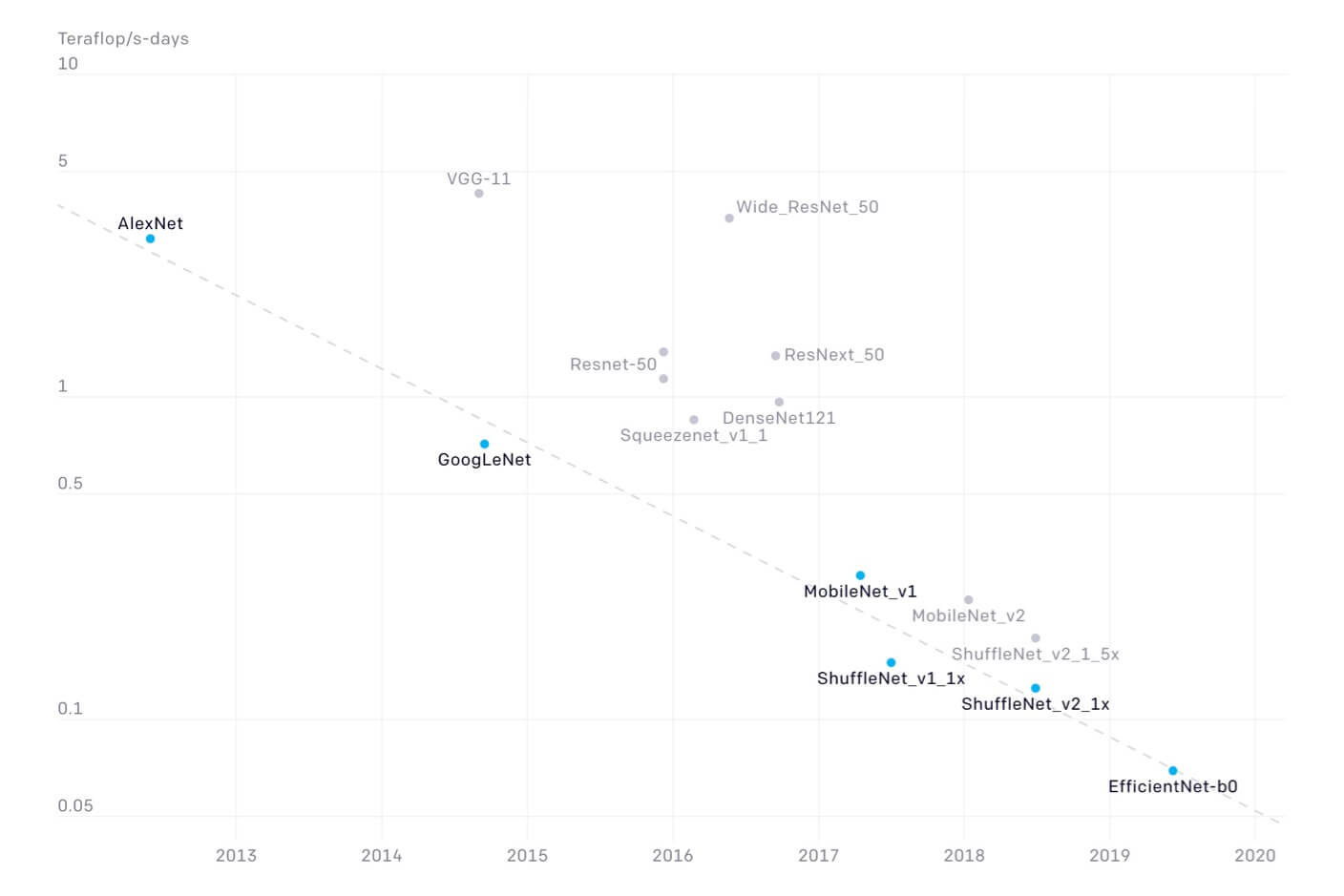
Total amount of compute in teraflops/s-days used to train to AlexNet level performance. Lowest compute points at any given time shown in blue. All points measured shown in gray. Image and caption: OpenAI
Though there are fewer data points, the authors found even faster rates of improvement over shorter periods in other popular capabilities such as translation and game-playing.
The Transformer algorithm, for example, took 61 times less computing power to surpass the seq2seq algorithm at English to French translation three years later. DeepMind's AlphaZero required eight times less compute to match AlphaGoZero at the game of Go only a year later. And OpenaAI Five Rerun used five times less computing power to overtake the world-champion-beating OpenAI Five at Dota 2 just three months later.
A Moore's Law for Machine Learning
Why track algorithmic efficiency? The authors say that three inputs drive progress in machine learning: available computing power, data, and algorithmic innovation. Computing power is easier to track, but improvements in algorithms are a bit more slippery.
Is there a kind of algorithmic Moore's Law in machine learning? Maybe. But there's not enough information to say yet, according to the authors.
Their work only includes a few data points (the original Moore's Law chart similarly had few observations). So any extrapolation is purely speculative. Also, the paper focuses on just a handful of popular capabilities and top programs. It's not clear if the observed trends can be generalized more widely.
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

That said, the authors say the measure may actually underestimate progress, in part because it hides the initial leap from impractical to practical. The computing power it would have taken to reach a benchmark's initial ability—say, AlexNet in image recognition—for prior approaches would have been so large as to be impractical. The efficiency gains to basically go from zero to one, then, would be staggering, but aren't accounted for here.
The authors also point out other existing measures for algorithmic improvement can be useful depending on what you're hoping to learn. Overall, they say, tracking multiple measures—including those in hardware—can paint a more complete picture of progress and help determine where future effort and investment will be most effective.
The Future of AI
It's worth noting the study focuses on deep learning algorithms, the dominant AI approach at the moment. Whether deep learning continues to make such dramatic progress is a source of debate in the AI community. Some of the field's top researchers question deep learning's long-term potential to solve the field's biggest challenges.
In an earlier paper, OpenAI showed the latest headline-grabbing AIs require a rather shocking amount of computing power to train, and that the required resources are growing at a torrid pace. Whereas growth in the amount of computing power used by AI programs prior to 2012 largely tracked Moore's Law, the computing power used by machine learning algorithms since 2012 has been growing seven times faster than Moore's Law.
This is why OpenAI is interested in tracking progress. If machine learning algorithms are getting more expensive to train, for example, it's important to increase funding to academic researchers so they can keep up with private efforts. And if efficiency trends prove consistent, it'll be easier to anticipate future costs and plan investment accordingly.
Whether progress continues unabated, Moore's-Law-like for years to come or soon hits a wall remains to be seen. But as the authors write, if these trends do continue on into the future, AI will get far more powerful still, and maybe sooner than we think.
Image credit: Frankie Lopez / Unsplash

Related Articles

OpenAI Agent Breaks Free and Hacks Hugging Face

Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?

Is AI Making Us Dumber?
OpenAI Agent Breaks Free and Hacks Hugging Face
Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?
Is AI Making Us Dumber?
What we’re reading