How Future AI Could Recognize a Kangaroo Without Ever Having Seen One

Share
AI is continuously taking on new challenges, from detecting deepfakes (which, incidentally, are also made using AI) to winning at poker to giving synthetic biology experiments a boost. These impressive feats result partly from the huge datasets the systems are trained on. That training is costly and time-consuming, and it yields AIs that can really only do one thing well.
For example, to train an AI to differentiate between a picture of a dog and one of a cat, it’s fed thousands—if not millions—of labeled images of dogs and cats. A child, on the other hand, can see a dog or cat just once or twice and remember which is which. How can we make AIs learn more like children do?
A team at the University of Waterloo in Ontario has an answer: change the way AIs are trained.
Here’s the thing about the datasets normally used to train AI—besides being huge, they’re highly specific. A picture of a dog can only be a picture of a dog, right? But what about a really small dog with a long-ish tail? That sort of dog, while still being a dog, looks more like a cat than, say, a fully-grown Golden Retriever.
It’s this concept that the Waterloo team’s methodology is based on. They described their work in a paper published on the pre-print (or non-peer-reviewed) server arXiv last month. Teaching an AI system to identify a new class of objects using just one example is what they call “one-shot learning.” But they take it a step further, focusing on “less than one shot learning,” or LO-shot learning for short.
LO-shot learning consists of a system learning to classify various categories based on a number of examples that’s smaller than the number of categories. That’s not the most straightforward concept to wrap your head around, so let’s go back to the dogs and cats example. Say you want to teach an AI to identify dogs, cats, and kangaroos. How could that possibly be done without several clear examples of each animal?
The key, the Waterloo team says, is in what they call soft labels. Unlike hard labels, which label a data point as belonging to one specific class, soft labels tease out the relationship or degree of similarity between that data point and multiple classes. In the case of an AI trained on only dogs and cats, a third class of objects, say, kangaroos, might be described as 60 percent like a dog and 40 percent like a cat (I know—kangaroos probably aren’t the best animal to have thrown in as a third category).
“Soft labels can be used to represent training sets using fewer prototypes than there are classes, achieving large increases in sample efficiency over regular (hard-label) prototypes,” the paper says. Translation? Tell an AI a kangaroo is some fraction cat and some fraction dog—both of which it’s seen and knows well—and it’ll be able to identify a kangaroo without ever having seen one.
If the soft labels are nuanced enough, you could theoretically teach an AI to identify a large number of categories based on a much smaller number of training examples.
The paper’s authors use a simple machine learning algorithm called k-nearest neighbors (kNN) to explore this idea more in depth. The algorithm operates under the assumption that similar things are most likely to exist near each other; if you go to a dog park, there will be lots of dogs but no cats or kangaroos. Go to the Australian grasslands and there’ll be kangaroos but no cats or dogs. And so on.
To train a kNN algorithm to differentiate between categories, you choose specific features to represent each category (i.e. for animals you could use weight or size as a feature). With one feature on the x-axis and the other on the y-axis, the algorithm creates a graph where data points that are similar to each other are clustered near each other. A line down the center divides the categories, and it’s pretty straightforward for the algorithm to discern which side of the line new data points should fall on.
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

The Waterloo team kept it simple and used plots of color on a 2D graph. Using the colors and their locations on the graphs, the team created synthetic data sets and accompanying soft labels. One of the more simplistic graphs is pictured below, along with soft labels in the form of pie charts.
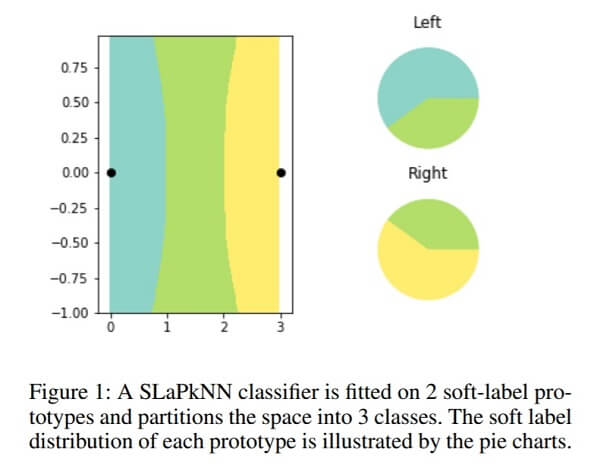
Image Credit: Ilia Sucholutsky & Matthias Schonlau
When the team had the algorithm plot the boundary lines of the different colors based on these soft labels, it was able to split the plot up into more colors than the number of data points it was given in the soft labels.
While the results are encouraging, the team acknowledges that they’re just the first step, and there’s much more exploration of this concept yet to be done. The kNN algorithm is one of the least complex models out there; what might happen when LO-shot learning is applied to a far more complex algorithm? Also, to apply it, you still need to distill a larger dataset down into soft labels.
One idea the team is already working on is having other algorithms generate the soft labels for the algorithm that’s going to be trained using LO-shot; manually designing soft labels won’t always be as easy as splitting up some pie charts into different colors.
LO-shot’s potential for reducing the amount of training data needed to yield working AI systems is promising. Besides reducing the cost and the time required to train new models, the method could also make AI more accessible to industries, companies, or individuals who don’t have access to large datasets—an important step for democratization of AI.
Vanessa has been writing about science and technology for eight years and was senior editor at SingularityHub. She's interested in biotechnology and genetic engineering, the nitty-gritty of the renewable energy transition, the roles technology and science play in geopolitics and international development, and countless other topics.
Related Articles

Google DeepMind Plans to Track AGI Progress With These 10 Traits of General Intelligence

Tech Companies Are Blaming Massive Layoffs on AI. What’s Really Going On?

Hackers Are Automating Cyberattacks With AI. Defenders Are Using It to Fight Back.
Google DeepMind Plans to Track AGI Progress With These 10 Traits of General Intelligence
Tech Companies Are Blaming Massive Layoffs on AI. What’s Really Going On?
Hackers Are Automating Cyberattacks With AI. Defenders Are Using It to Fight Back.
What we’re reading