How DeepMind’s Latest AI Hints at Machines That Think More Like Us

Share
I once asked a deep learning researcher what he’d like for Christmas.
His answer? “More labeled datasets.”
Nerd jokes aside, the lack of so-called “labeled” training data in deep learning is a real problem. Deep learning relies on millions upon millions of examples to tell the algorithm what to look for—cat faces, vocal patterns, or humanoid things strolling on the street. A deep learning algorithm is only as good as the data it’s trained on—“garbage in, garbage out”—so accurately gathering and labeling existing data is essential.
For the human researchers tasked with the job, carefully parsing the training data is a horrendously boring and time-consuming process.
It’s not just researcher agony. The lack of training datasets is often the linchpin in developing new applications for deep learning.
But what if this reliance on data is actually non-essential? What if there’s a way for machines to learn as quickly and flexibly as humans do? A toddler rapidly figures out what a pizza is from a few examples, even if the toppings are vastly different. State-of-the-art deep neural nets can’t.
In last week’s issue of Science, DeepMind unveiled an algorithm that displays the first steps in transfer learning. When shown a series of related 2D images from a camera, the algorithm can figure out the 3D environment and predict new views of the scene—even those it had never before encountered in its training examples.
The deep neural net, dubbed the Generative Query Network (GQN), could analyze 2D views via a simulated camera to control a digital robotic arm to navigate a 3D environment, suggesting potential applications in robotics.
That’s not even the impressive part: when researchers peeked into its AI brain, they found that the network captured the “essence” of each 3D scene, in that its internal structure represents meaningful aspects of the scene—for example, the type or color of an object. These real-world-based representations allowed the deep neural net to easily replace an object with another in the same scene without crashing.
“[This is] probably most fascinating about the study,” said Dr. Matthias Zwicker at the University of Maryland, who wasn’t involved in the study.
The technique “introduces a number of crucial contributions” that will likely help robots navigate real-world, complex environments in the future, he added.
Greedy Algorithms
You’ve probably heard of deep learning by now: it’s the method that’s rejuvenated the entire field of machine learning, lending itself to face recognition algorithms, voice-mimicking systems, Google Now, machine translation, self-driving cars, AI-based cancer diagnosticians, automatic caption generators, and…I could go on.
But deep learning has a serious problem: it needs human help.
Mimicking the human brain, deep learning relies on artificial neural networks with layers of “neurons” that stack like a gourmet sandwich. Like biological brains, these artificial neurons receive input from multiple peers, perform calculations, and forward the outputs to other neurons. Within a neural net the connections are fixed; training helps them adjust the computation of each neuron’s output. The training process is iterative and similar to tuning a guitar—with humans acting as supervisors telling the network what exactly it’s trying to learn (is it a pizza or not?).
Unshackling deep learning from this labeled data requirement would fundamentally change the intelligence landscape. Humans, after all, often don’t rely on other people for learning new skills. This is partly what unsupervised transfer learning is trying to do: have a machine figure out the goal based on raw input data alone, without requiring additional information from their human supervisors.
Encode-Decode Network
DeepMind’s new GQN relies on a process remarkably similar to how humans learn.
First, an encoder network analyzes visual inputs—the raw pixels—and churns the data into models of a scene. It forms a mathematical “representation” of what the scene describes, and each additional observation by the neural net adds to the richness of that representation. Here, the network can adapt to changes in the environment by efficiently encoding important details into a compact, high-level “idea.”
The next part is a decoder network: this part interprets the representations and offers solutions depending on the specific task at hand. In this way, the encoder network (and its “understandings”) can be used with different decoders, generating solutions to a vast array of problems. This setup allows the GQN to account for uncertainty, the authors explained, so that it can try to understand scenes that are severely occluded from view.
It’s like a child gaining an understanding of what counts as a pizza: they may not be able to describe it, but can use their mental picture of a pizza to figure out if the thing in front of them falls into that category—even if it’s a dish they’ve never seen before.
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

Of course, compared to human eyes, computers are at a disadvantage: rather than seeing scenes in 3D, cameras capture the environment in 2D. The DeepMind team cleverly tackles the problem by rendering 3D environments from 2D images using a standard computer algorithm.
“This approach allows them to produce 2D views from any desired viewpoint,” explained Zwicker.
Using two nearby views from the same scene as input, the team then trained their GQN to predict new views of the 3D environment—a type of transfer learning. Because the encoder network doesn’t know what types of questions the decoder needs to tackle, it learns to generate representations including all information in a scene—for example, what the objects are, where they’re located in space, the room layout, and so on.
“The GQN will learn by itself what these factors are, as well as how to extract them from pixels,” the authors said. The decoder network then takes this concise, abstract description of a scene and fills in any gaps in the representations.
When pitted against a virtual maze with multiple rooms and corridors, the GQN could tease out its structure by aggregating multiple observations from different vantage points. In another test, the GQN was tasked to control a virtual robotic arm reaching for a colored ball. Rather than the conventional approach of analyzing raw pixels, the GQN zipped up the scene into compact representations, which were in turn used to control the robotic arm.
It makes the process much more efficient and faster, all without human help, the authors said.
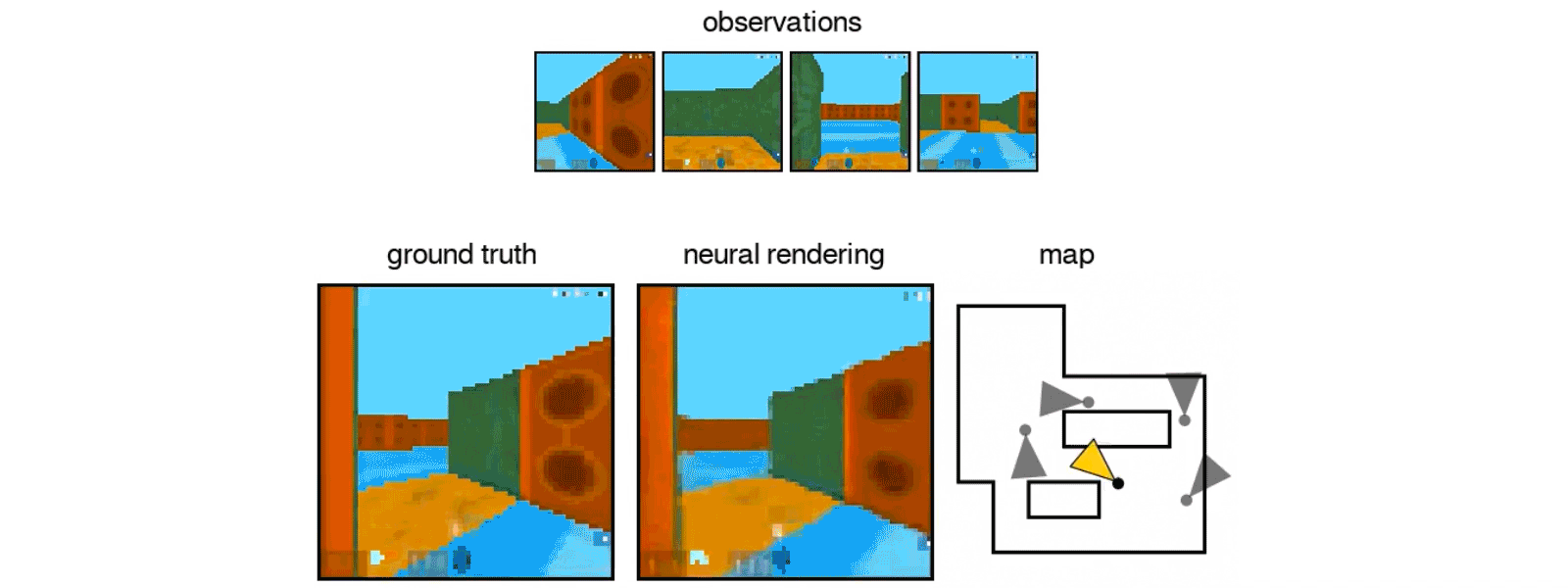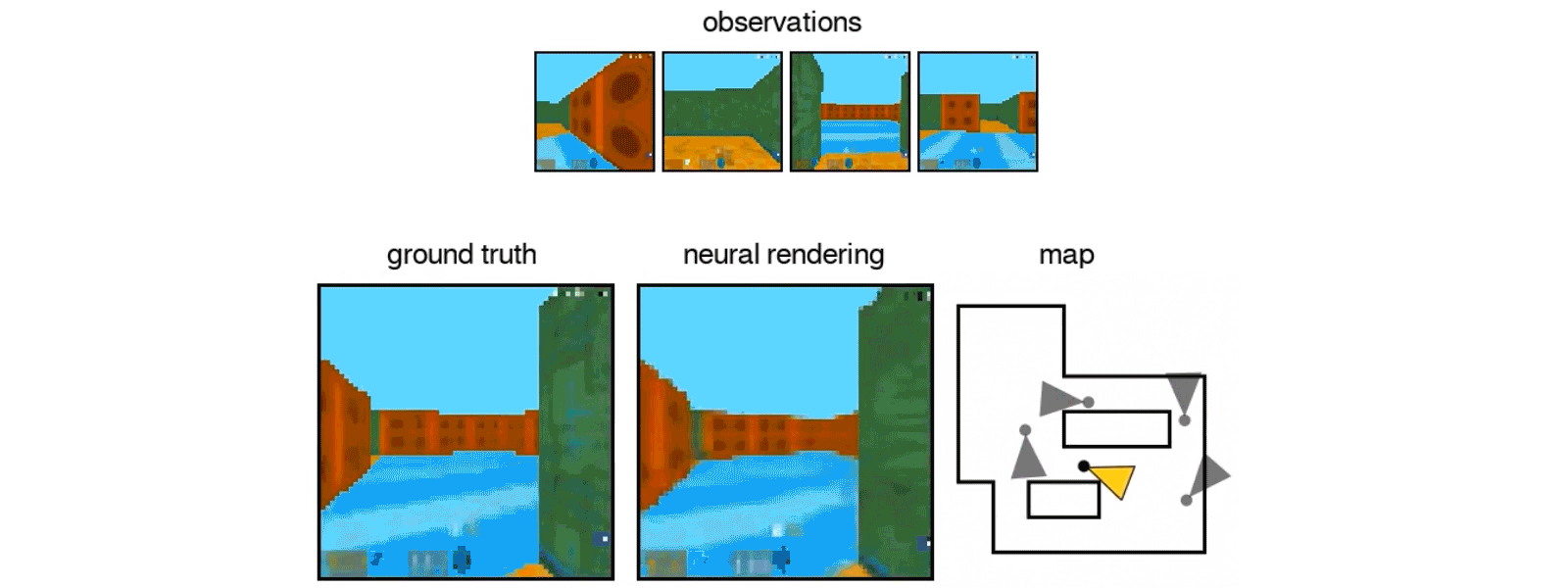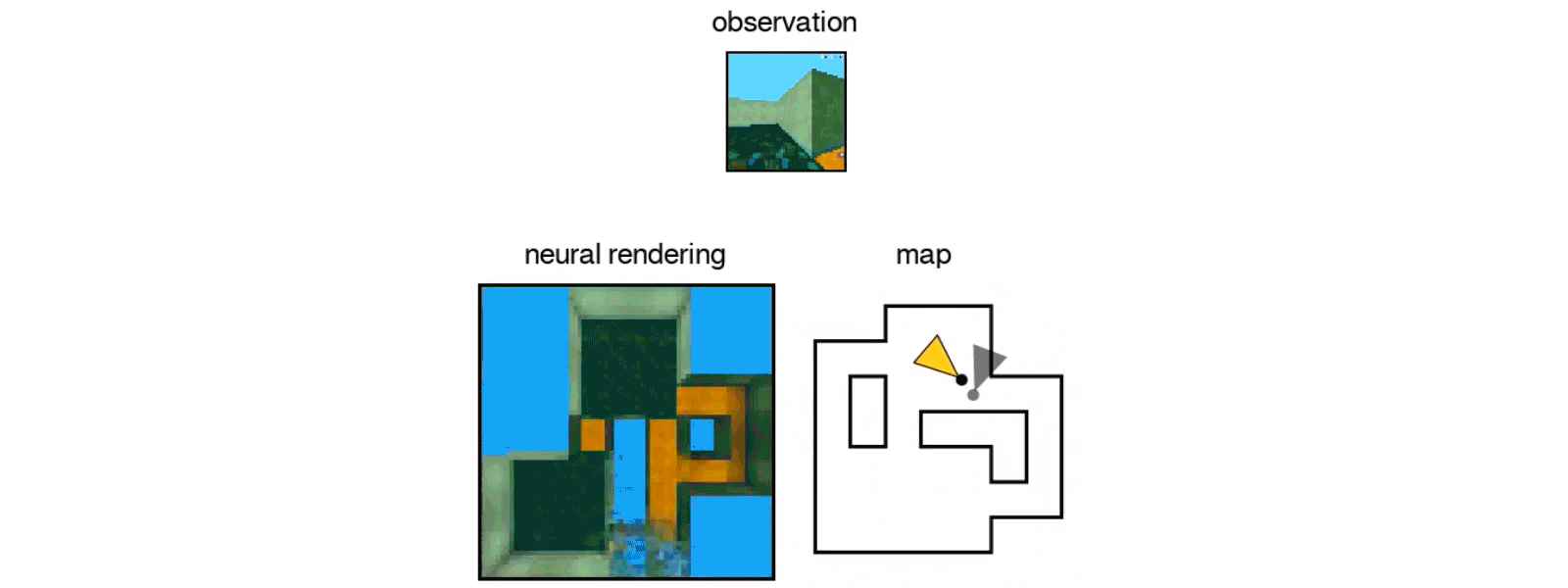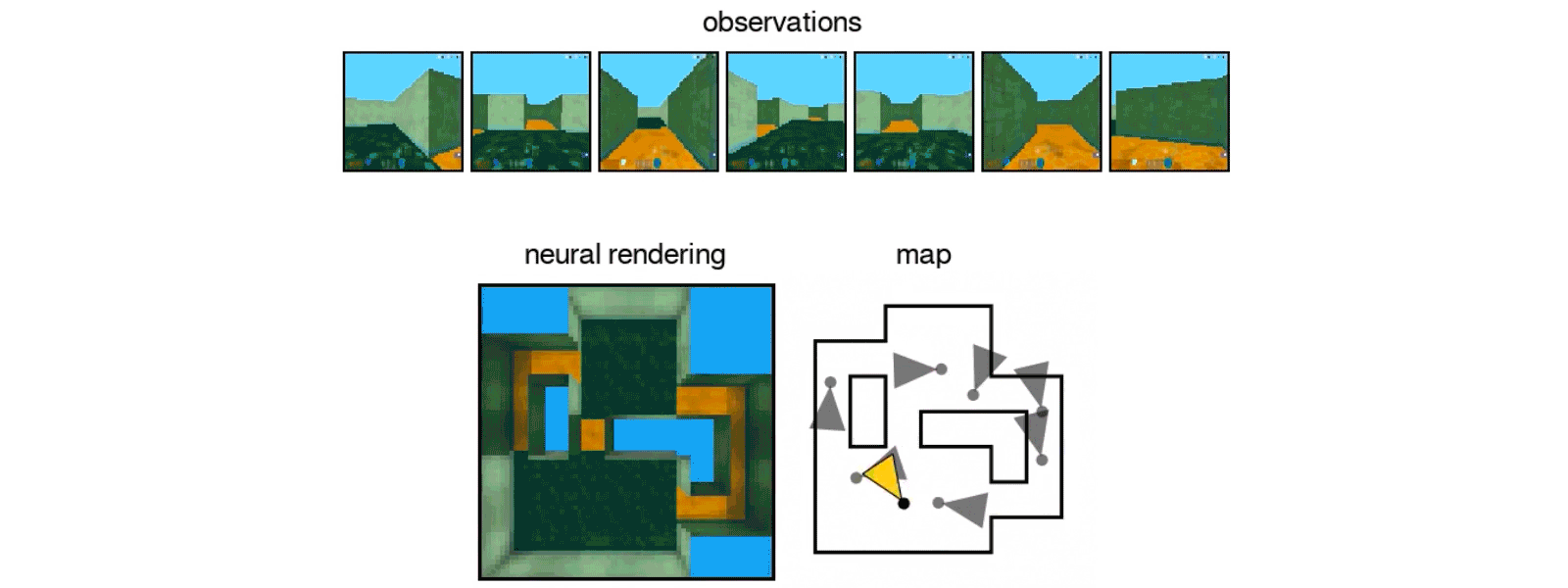
The algorithm reconstructs a maze based on a few viewpoints. Image Credit: DeepMind
This isn’t the first try at unsupervised learning. Reinforcement learning, adapted from psychology, “teaches” algorithms to learn based on how much reward they get for an action. DeepMind and OpenAI are both betting on deep reinforcement learning as a way to get to transfer learning, with OpenAI releasing a digital “gym” to train a single algorithm to learn everything that can be learned within the digital realm.
Already there have been successes: AlphaGo Zero, for example, combined deep reinforcement learning with playing itself (“self-play”) to become arguably the strongest Go player in history, without an ounce of human input. OpenAI’s Unsupervised Sentiment Neuron learns to predict the next character in Amazon reviews, but can transfer that learning for sentiment analysis into text. Recently, they launched the “Retro Contest” to encourage machine learning researchers to develop algorithms that can generalize from previous experience.
DeepMind’s current study takes transfer learning out of the gaming world and sticks it into something more concrete: parsing scenes. That’s not to say that the GQN is ready for the real world. Most experiments were restricted to simple 3D “toy” scenes comprising only a few objects, so it’ll still take some work for the algorithm to understand our complex and messy world.
But the technique offers a path towards that goal.
“Our work illustrates a powerful approach to machine learning…that holistically extracts these representations from images, paving the way toward fully unsupervised scene understanding, imagination, planning and behavior,” the authors concluded.
In other words, everything that’ll make a machine think more like a human.
Image Credit: DeepMind
Related Articles

OpenAI Agent Breaks Free and Hacks Hugging Face

Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?

Is AI Making Us Dumber?
OpenAI Agent Breaks Free and Hacks Hugging Face
Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?
Is AI Making Us Dumber?
What we’re reading