An AI Tool Just Revealed Almost 200 New Systems for CRISPR Gene Editing
Share
CRISPR has a problem: an embarrassment of riches.
Ever since the gene editing system rocketed to fame, scientists have been looking for variants with better precision and accuracy.
One search method screens for genes related to CRISPR-Cas9 in the DNA of bacteria and other creatures. Another artificially evolves CRISPR components in the lab to give them better therapeutic properties—like greater stability, safety, and efficiency inside the human body.
This data is stored in databases containing billions of genetic sequences. While there may be exotic CRISPR systems hidden in these libraries, there are simply too many entries to search.
This month, a team at MIT and Harvard led by CRISPR pioneer Dr. Feng Zhang took inspiration from an existing big-data approach and used AI to narrow the sea of genetic sequences to a handful that are similar to known CRISPR systems.
The AI scoured open-source databases with genomes from uncommon bacteria—including those found in breweries, coal mines, chilly Antarctic shores, and (no kidding) dog saliva.
In just a few weeks, the algorithm pinpointed thousands of potential new biological “parts” that could make up 188 new CRISPR-based systems—including some that are exceedingly rare.
Several of the new candidates stood out. For example, some could more precisely lock onto the target gene for editing with fewer side effects. Other variations aren’t directly usable but could provide insight into how some existing CRISPR systems work—for example, those targeting RNA, the “messenger” molecule directing cells to build proteins from DNA.
“Biodiversity is such a treasure trove,” said Zhang. “Doing this analysis kind of allows us to kill two birds with one stone: both study biology and also potentially find useful things,” he added.
A Wild Hunt
Although CRISPR is known for its gene editing prowess in humans, scientists first discovered the system in bacteria where it combats viral infections.
Scientists have long collected bacterial samples from nooks and crannies all over the globe. Thanks to increasingly affordable and efficient DNA sequencing, many of these samples—some from unexpected sources such as pond scum—have had their genetic blueprint mapped out and deposited into databases.
Zhang is no stranger to the hunt for new CRISPR systems. “A number of years ago, we started to ask, ‘What is there beyond CRISPR, and are there other RNA-programmable systems out there in nature?’” Zhang told MIT News earlier this year.
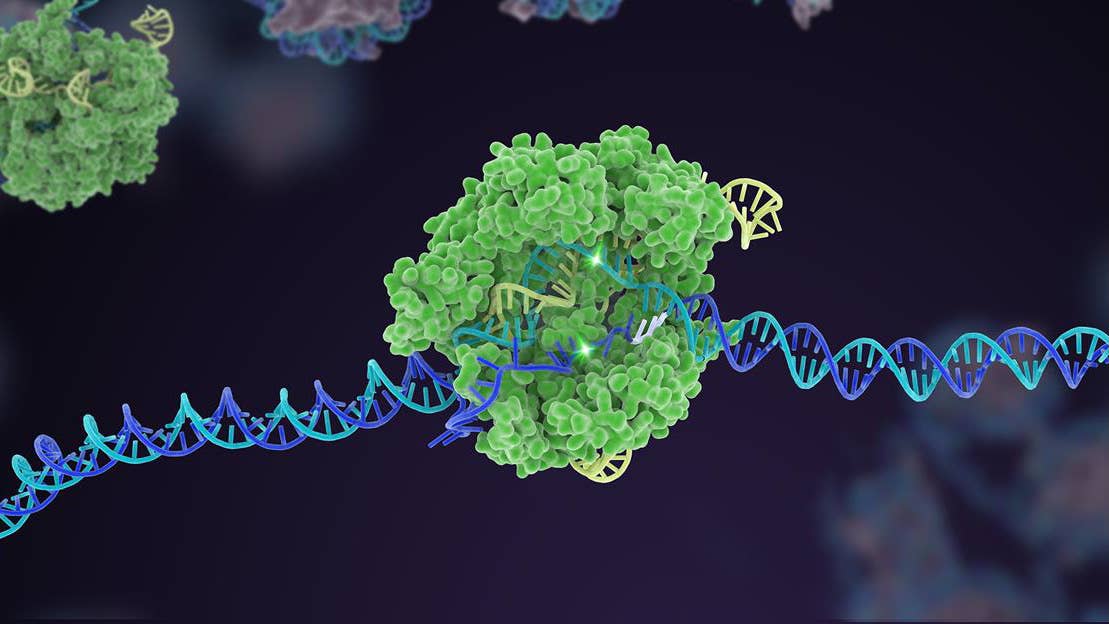
CRISPR is made up of two structures. One is a “bloodhound” guide RNA sequence, usually about 20 bases long, that targets a particular gene. The other is the scissors-like Cas protein. Once inside a cell, the bloodhound finds the target, and the scissors snip the gene. More recent versions of the system, such as base editing or prime editing, use different types of Cas proteins to perform single-letter DNA swaps or even edit RNA targets.
Back in 2021, Zhang’s lab traced the origins of the CRISPR family tree, identifying an entirely new family line. Dubbed OMEGA, these systems use foreign guide RNAs and protein scissors, yet they could still readily snip DNA in human cells cultured in petri dishes.
More recently, the team expanded their search to a new branch of life: eukaryotes. Members in this family—including plants, animals, and humans—have their DNA tightly wrapped inside a nut-like structure. Bacteria, in contrast, don’t have these structures. By screening fungi, algae, and clams (yup, biodiversity is weird and awesome), the team found proteins they call Fanzors that can be reprogrammed to edit human DNA—a first proof that a CRISPR-like mechanism also exists in eukaryotes.
But the goal isn’t to hunt down shiny, new gene editors just for the sake of it. Rather, it’s to tap nature’s gene editing prowess to build a collection of gene editors, each with its own strengths, that can treat genetic disorders and help us understand our body’s inner workings.
Be Part of the Future
Sign up to receive top stories about groundbreaking technologies and visionary thinkers from SingularityHub.

Collectively, scientists have discovered six main CRISPR systems—some collaborate with different Cas enzymes, for instance, while others specialize in either DNA or RNA.
“Nature is amazing. There’s so much diversity,” Zhang said. “There are probably more RNA-programmable systems out there, and we’re continuing to explore and will hopefully discover more.”
Bioengineering Scrabble
That’s what the team built the new AI, called FLSHclust, to do. They transformed technology that analyzes bewilderingly large datasets—like software highlighting similarities in large deposits of document, audio, or image files—into a tool to hunt genes related to CRISPR.
Once complete, the algorithm analyzed gene sequences from bacteria and collected them into groups—a bit like clustering colors into a rainbow, grouping similar colors together so it’s easier to find the shade you’re after. From here, the team honed in on genes associated with CRISPR.
The algorithm combed through multiple open-source databases including hundreds of thousands of genomes from bacteria and archaea and millions of mystery DNA sequences. In all, it scanned billions of protein-encoding genes and grouped them into roughly 500 million clusters. In these, the team identified 188 genes no one has yet associated with CRISPR and that could make up thousands of new CRISPR systems.
Two systems, developed from microbes in the guts of animals and the Black sea, used a 32-base guide RNA instead of the usual 20 used in CRISPR-Cas9. Like a search query, the longer it is, the more precise the results. These longer guide RNA “queries” suggest the systems could have fewer side effects. Another system is like a previous CRISPR-based diagnostic system called SHERLOCK, which can rapidly sense a single DNA or RNA molecule from an infectious invader.
When tested in cultured human cells, both systems could snip a single strand of the targeted gene and insert small genetic sequences at roughly 13 percent efficiency. It doesn’t sound like much, but it’s a baseline that can be improved.
The team also uncovered genes for a new CRISPR system targeting RNA previously unknown to science. Only found after close scrutiny, it seems this version and any yet to be discovered aren’t easily captured by sampling bacteria around the world and are thus extremely rare in nature.
“Some of these microbial systems were exclusively found in water from coal mines,” said study author Dr. Soumya Kannan. “If someone hadn’t been interested in that, we may never have seen those systems.”
It’s still too early to known whether these systems can be used in human gene editing. Those that randomly chop up DNA, for example, would be useless for therapeutic purposes. However, the AI can mine a vast universe of genetic data to find potential “unicorn” gene sequences and is now available to other scientists for further exploration.
Image Credit: NIH
Dr. Shelly Xuelai Fan is a neuroscientist-turned-science-writer. She's fascinated with research about the brain, AI, longevity, biotech, and especially their intersection. As a digital nomad, she enjoys exploring new cultures, local foods, and the great outdoors.
Related Articles

Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?

Is AI Making Us Dumber?

CAR T Revolutionized How We Treat Blood Cancers. Now It’s Closing In on Solid Tumors.
Anthropic Says Chatbots Have What May Be a Key Feature of Consciousness. Are They Right?
Is AI Making Us Dumber?
CAR T Revolutionized How We Treat Blood Cancers. Now It’s Closing In on Solid Tumors.
What we’re reading